Orchestrator of Orchestrators – Workflow Engine Deep Dive
As discussed in the post Orchestrator of Orchestrators – Workflow Engine, the engine is comprised of a REST API component and a opre service component of which both run in their own processes.
The REST API component is built around NGINX, Gunicorn & Flask. The REST API component uses the workflow engine database to manage workflow requests. Currently there is no direct interaction between the REST API component and the core service component, all ‘interaction’ is via the database. On the ‘todo’ list is to move to a messaging model using Redis or RabbitMQ for component communication and in addition this will allow the services to be scaled horizontally using a master/worker design, this will use the messaging system to delegate workflow requests to the worker core service components and add in service resliency.
A side note on the messaging system, I originally used a messaging system (wrapper around Redis) instead of each service (as described in the post Orchestrator of Orchestrators but found that this was more trouble than its worth in terms of ensuring I had positive acknowledgments to requests sent, it almost ended up with me writing the wrappers and client code to act like a REST API, so I removed this and implemented a REST API for each microservice instead – Why reinvent the wheel ? For internal communication in a microservice (like the workflow engine) I can see the benefits as the dependency on request acknowledgements are not as high as the system will be constantly checking workflow request progress.
In this article we focus on the core service of the workflow engine, looking at how the service is constructed and how a workflow request is progressed.
The core engine service is written in Python run as a Linux service, after the initial startup code initialises it creates a new thread for the main workflow engine. The main engine then performs tasks like checking for any pending workflows to validate or run, checking running (inflight) workflows for progress and for any orphan workflows (workflow that have got lost or out of sync due to system restart or crash whilst a workflow was running).
Engine Initialization
On start up the engine initializes a few background tasks before starting the engine thread.
Metric Collection
The system exports metrics like number of running workflows, failed and successful workflows to Prometheus, as usual with a Prometheus client (or server depending on your view point), we create the required Gauge’s, start a HTTP server and expose some internal functions to allow the workflow code to update the metrics by calling a single function.
This is a work in progress but I have Grafana pulling the stats from Prometheus on to a dashboard to display the following metrics.
- Running Workflow Requests Count
- Running Workflow Request Tasks Count
- Pending Workflow Request Tasks Count
- Completed Workflow Request Task Count
This is not a big priority right now, but the framework is in place so I can add new metrics easily as I need to.
Logging
I use the standard Python logging library to log to a file on disk, this is the service logging file of which the logs are specific to the engine and exclude any detail logging on the workflow instances. The creation, termination of workflows is logged but the workflow instances themselves log to dedicated log files.
A second logging instance is also created to log to a syslog server. The use of this is selective in the code and is generally used for logging the progress of a workflow instance, so the creation, current state, termination. Again this is not the detailed workflow request instance log but serves to provide overall system status to a syslog server. The UI uses this to display progress for a workflow instance for example.
Presence
I previously mentioned that I had written a client wrapper around Redis for messaging, well another part of this was a ‘Presence’ system. The presence system client is used by all microservices (both REST API and core service components) and each client creates a ‘presence’ on startup. The presence is updated by the client in a 5s interval keeping the presence and status of the client updated. If the presence information is not updated in 15s, the presence entry is dropped. This allows either microservice code or a end user to understand the current system status at a microservice level.
The following are examples of the presence system as seen on Redis for the workflow REST API and core service. This is the data the presence client outputs to Redis every 5s. Each client generates a UUID on startup so updates always overwrite the current entry keeping the presence state fresh. Data about the platform the service is running on like the host OS and Python version are also added to this data from the client.
{
"instance_id": "3fd96f66340c44629673e12ccac5eff9",
"host": "dev01.labs.haystacknetworks.com",
"platform": [
"CentOS Linux",
"7.9.2009",
"Core"
],
"python": [
3,
6,
8,
"final",
0
],
"last_update": "2021-09-06T06:43:04.026795",
"started": "2021-09-06T06:42:01.717095",
"uptime": "0:01:02.309700",
"services": {
"msg": {
"64e482fdb6e94ab9b5877e442d23355f": {
"service_name": "workflow-svc",
"msg_group": "workflow",
"promiscuous": false
}
}
}
}{
"instance_id": "57818f7c95b34107b381c2579de50b72",
"host": "dev01.labs.haystacknetworks.com",
"platform": [
"CentOS Linux",
"7.9.2009",
"Core"
],
"python": [
3,
6,
8,
"final",
0
],
"last_update": "2021-09-06T06:42:57.217327",
"started": "2021-09-01T15:58:01.633833",
"uptime": "4 days, 14:44:55.583494",
"services": {
"msg": {
"44df6f2ee68141c18325bebef2349061": {
"service_name": "workflow-api",
"msg_group": "api",
"promiscuous": false
}
}
}
}Database
All services connect to a PostGres database. Each microservice has its own dedicated database, so for the workflow engine microservice both the REST API and core services connect to the same database but other microservices or anything outside of the workflow microservice does not connect to this database. All outside interaction is done via the REST API.
Workflow Monitor
Finally the workflow monitor thread is started. We will look at this in detail in the next section, but as far as the main thread is concerned, once the workflow monitor thread is started it enters a loop which checks that the workflow thread is still alive and checks for a service shutdown. In the case that either event occurs the main thread will gracefully attempt to terminate the presence system client and database connections and then gracefully exit the main thread after logging details of the shutdown.
Workflow Monitor
The workflow monitor thread calls four main functions periodically, these are:
- self._check_pending_validation()
- self._check_pending_workflows()
- self._inflight.check_inflight_workflows()
- self._check_orphan_workflows()
Pending Validation
When a workflow request is submitted the request is validated before a workflow instance is created to run the workflow. The validation takes the input provided in the request and checks that all required data has been provided. In the first article on the workflow engine we discussed the Templates. The validation uses the defined template to check that the provided data is complete.
The template is parsed for required variables and inputted variables in the request data are checked to ensure they are present. If this process is successful the workflow will be marked as validated which means it can progress to the next stage of scheduling the workflow request. If the validation fails the request will be marked as validation failed and no more action will be taken on the workflow request.
Recall that workflow requests use a versioning scheme so the requestor of the workflow request can resubmit the same workflow with new data and the workflow request will be run through validation again using the updated revision.
The requestor is required to poll the status of the request via the REST API.
When a request is submitted, it can be submitted for validation only or for validation & scheduling. If submitted with a schedule either ‘now’ or a future date/time, a successful validation will be processed by the pending_workflows() function.
Pending Workflows
Once a workflow request has been successfully validated and the scheduled date/time indicates that the workflow request should be executed it will have a validation status of validated and a workflow status of pending.
The pending workflow function checks the database periodically for requests in the above described states, for each request found that requires execution, the function passes this workflow request to a class called ‘workflow_build’ instantiated for a specific workflow request.
Workflow Build Class
The workflow request runs within its own thread, it comprises a few classes within this thread that makes up the entire workflow request pipeline including the tasks to be run. A little more on this later, first the workflow build class.
The workflow build class is instantiated with a workflow request record from the database. First, there is a class called ‘Workflow’ that is instantiated, this is the class that the new thread is start within. The thread is started by the workflow build class once all requirements are met for creating the workflow. The Workflow instance is passed the workflow request details including trace ID, workflow variables from the request, workflow ID and revision IDs. At this point the Workflow instance only creates some state attributes (see the previous article for a reminder of these state vars) and sets the workflow state internally as created.
The Workflow class and thread including all child threads (tasks) do not have access to the database. The idea is that a workflow thread is a self contained execution of a workflow request. The output of this workflow is a state (Success, Failed, Exception, etc) and error text if provided. The core engine monitors the Workflow thread to get the status and update the database when required therefore keeping a separation of duties and access between the engine and the workflow request process.
Once the Workflow instance is created, the Workflow Build class then uses the required template to created a Directed Acyclic Graph (DAG) of the tasks that need to be created and run for the workflow. The DAG (once created) provides a ordered pipeline of tasks to run with dependencies on successful parent task execution. For audit purposes and re-running, the DAG is added to the database with the current revision number.
Each task in the DAG (which at this point is not actually a task, its a UUID and a abstract task reference) is parsed in order and a subclass of ‘Task’ is instantiated, this subclass ‘Task’ class instance is what we discussed in the previous article. Its a class derived from class Task written to perform a specific task. The examples we used were a single step in the creation of a Terraform PTFE run or an Ansible AWX Job template.
Time for a diagram showing where we are at this stage in a workflow request.
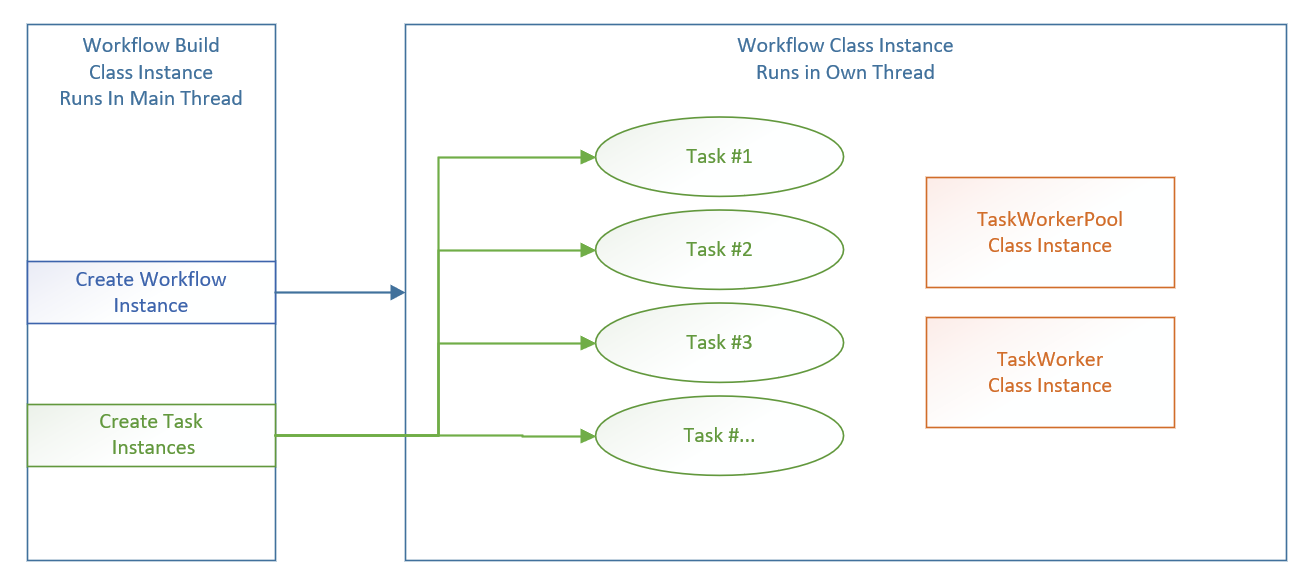
As described, the image above shows the Workflow class instance created by the Workflow Build class instance and additionally the tasks have also been created by the Workflow Build class and inserted into the Workflow class instance to own those class instances. Also depicted in the diagram are two other classes we have not spoken about yet – TaskWorkerPool and TaskWorker, but before we discuss those lets take a look at another diagram depicting the hierarchy of the Task classes.
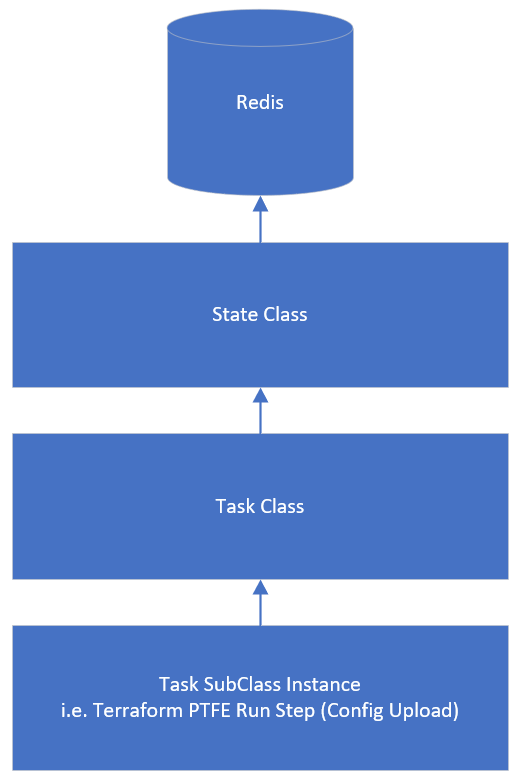
We have touched on this a few times but to visualize the Tasks and the related classes the diagram above shows the connections between these classes. Starting bottom up, we have the Task Subclass. This class is written to perform a single task and is referenced in the workflow template.
This task derives from the Task class which is in effect the controller of the task sub class. it ensures that the required methods are overridden in the Task subclass and provides methods for logging for the subclass and provides methods for the Workflow class to interact with the Task / Task subclass. This way the task subclass is written to only focus on the task at hand (i.e. using REST APIs with Terraform, Ansible, Red Hat Satellite, vCenter, ACI APIC or anything with a REST API) and the Task class deals with the communication to/from the Workflow instance and logging.
The Task class derives from the State class, this state class is a Redis wrapper that also overrides the Task and therefore Task subclass variable handing by overriding Python built-in methods of ‘__getattr__’ and ‘__setattr__’. The State class stores class variables in Redis under a Task instance specific UUID so these variables are saved even after the task terminates so they can be re-used if the workflow requires a restart, therefore the workflow always has a state and can be restarted from scratch or from the last known point before termination.
The Workflow class instance itself derives from the State class to have the same state features as described for a Task.
Task Workers
We saw in Workflow Class Instance diagram that we had an additional two classed we had not discussed before, namely ‘TaskWorkerPool’ and ‘TaskWorker’. The Workflow class instance creates an instance of the TaskWorkerPool class, this class spawns class instances of TaskWorker. A TaskWorker class instance runs in its own thread and within that thread manages the running of a Task subclass so each instance of a Task is running in its own thread managed by a TaskWorker. This ensures that a mis-behaving Task cannot impact the entire engine or even a Workflow instance, additionally this means we can have multiple Tasks running in parallel where this is permitted by the Task DAG created earlier.

Referencing a diagram used in the previous article, the two tasks called ‘no op task #1’ and ‘no op task #2’ would each be run at the same time as we have many TaskWorkers available (10 by default – can be increased). The maximum parallel running Tasks in a single Workflow request is 10 but this can be increased. TaskWorkers are reused for future Tasks in the Workflow request which means a TaskWorker is only assigned a Task at the moment the Task need to run. The TaskWorkerPool class instance manages the allocation of TaskWorker instances on behalf of the Workflow class instance.
So with all these threads isn’t there a problem with contention as we know that the CPython interpreter does not support true multi-threading ? Very true and we are using the Thread library and not the multi-processing library. First using the MP library causes pain passing data between processes, yes it can be done but its painful and offers us no benefit here. Why ?
Well As each task is indented to perform REST API calls to an external system of which we will get an immediate response or we have to poll the external system while the REST API call made is being processes (think starting an Ansible AWX job and waiting on result). So in reality even with many parallel running workflows and tasks, the tasks don’t need to poll the external systems every few nanoseconds, microseconds as we know generally any request that requires polling the endpoint will take a few seconds at minimum.
When the workflow class instance calls the Task method ‘ping’, this effectively wakes up the Task and says ‘give me your current status’ at which point the Task will make a REST API call to the external system to get the external system status (i.e. AWX job status) and map and return a valid Task status.
So trying to implement MP with all the complexities would offer no benefit at all and using the Thread library is a whole lot easier. I will say that I have a thought in my head to run the Workflow Instances in containers and maybe each task too, so we would have a TaskContainerWorkerPool class and TaskContainerWorker for example. This would mean this is true MP of course (well argue that down through K8 and the OS but you get my point), this would be more complex but something I would love to do if I had the time. The concept of separation and isolation in this regard is attractive, certainly for scaling up massively (not that this will ever be that big but I like to think in that way 🙂 )
To visualize this…
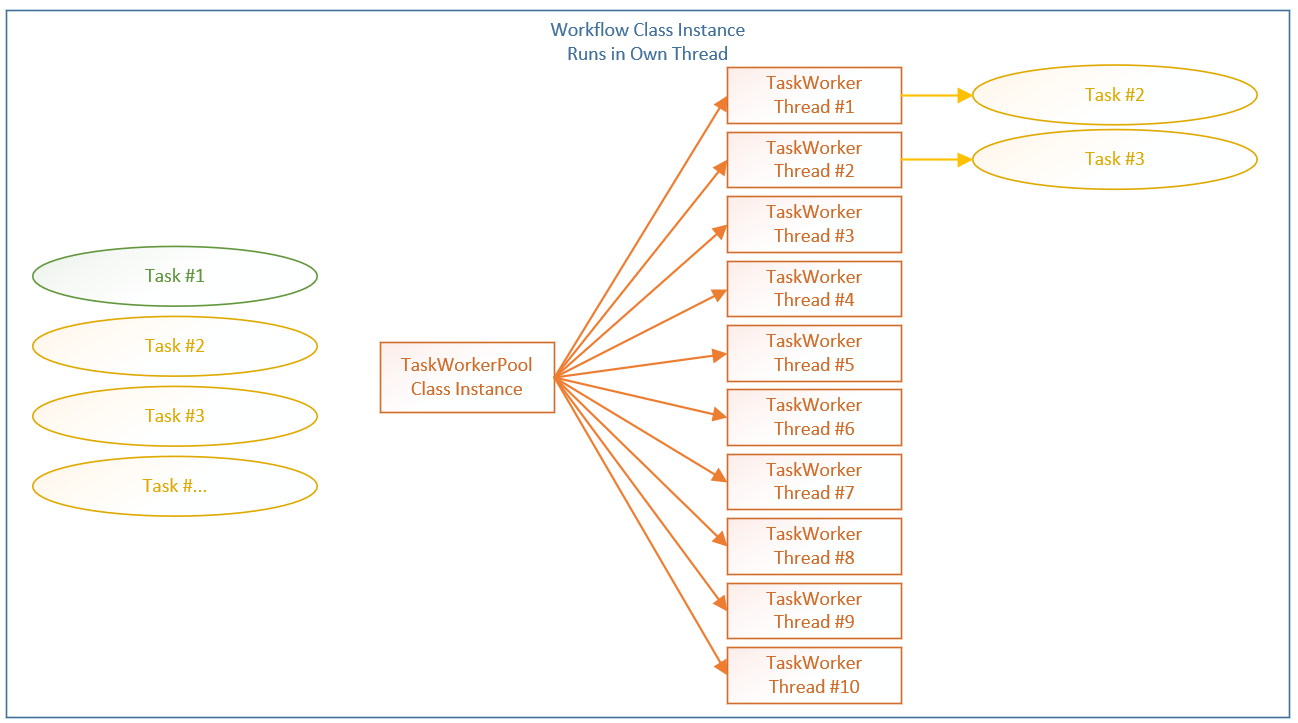
If we use an example with 3 tasks, the 2nd and 3rd task are dependant on the 1st task completing successfully according the the created DAG. If we assume the 1st task does complete successfully, then tasks 2 & 3 can be run in parallel. The above diagram shows the task instances for tasks 2 & 3 passed to the TaskWorkerPool by the Workflow instance. The TaskWorkerPool instance assigns task #2 to TaskWorker #1 and task #3 to TaskWorker #2. The assignment is based on a combination of round robin and availability, so in reality it might be that TaskWorkers #2 and #3 are used but it makes no difference. The Tasks ‘task_init’ and ‘run’ methods will be called by the Workflow instance once they have been assigned a TaskWorker.
So for the moment lets stop here. This is longer than I expected so I will pick this up in another article.