Orchestrator of Orchestrators – Workflow Engine
Here we discuss the workflow engine microservice which is part of the wider orchestration system project I tasked myself with. This is one part of the series of discussions about the system. The summary discussion page can be found here.
We briefly discussed the workflow engine microservice before, but to remind ourselves we have the basic requirement of having the workflow engine take a REST request with declarative input data which instructs the workflow engine to run a set of tasks defined by a template. The tasks are usually small python modules that call core orchestration system REST APIs to perform their tasks. These ‘ core orchestration systems’ are systems like Ansible AWX/Tower or Terraform TFE.
The job of the workflow engine is to co-ordinate the tasks to be performed by multiple orchestration/build systems in the correct order to have an outcome of a resource that has been created, modified or deleted. It should instruct these core systems to perform the task, monitor the progress and based on the final status of a task, decide if to continue to the next required task until completion or fail the workflow.
The engine is written entirely in Python.
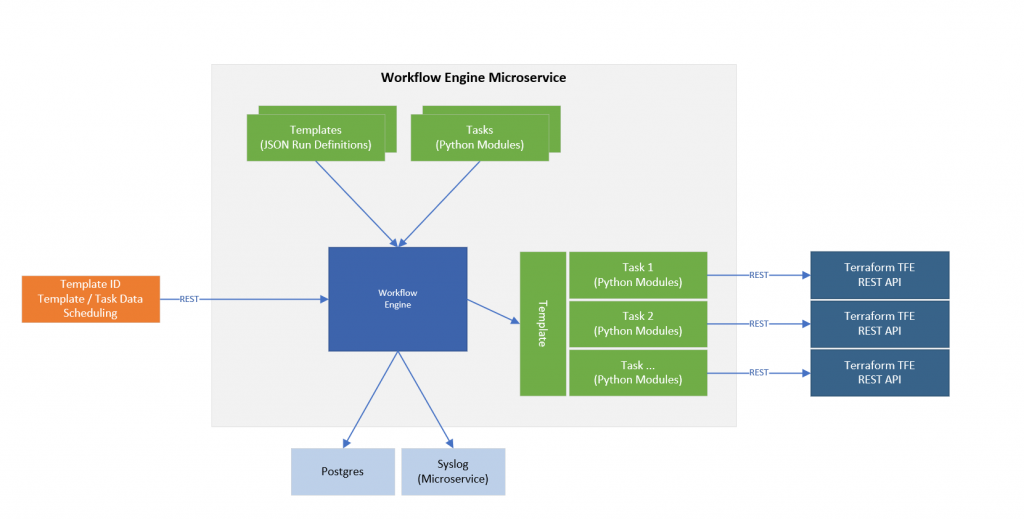
The diagram below depicts a high level view of what we want to achieve. From left to right we follow this process.
- An input via REST API, which provides the engine with a template to be used and a set of data that will be required by the templates tasks.
- The ‘Templates’ are declarative files which define which tasks to use with implicit or explicit task dependencies.
- The ‘Tasks’ are Python modules that are provided with input data, executed and monitored until the task completes.
- As shown each task uses an external systems REST API to instruct that system to perform a task.
I have talked a bit about external systems, what do I mean by these external systems. Using a example that we want to build a number of resources for a project, lets say a network (L2,L3) and 10 Linux Virtual Machines on that network. We may choose to use Terraform to build the basic infrastructure, so the network and the barebones VM’s (with network connectivity). We then want to use Ansible to configure, patch, secure, add monitoring the VM’s. We need to initiate two jobs – one on Terraform, take the output data (VM names, IPs, etc), then input this into Ansible to configure the VM’s. This is what the engine is doing, defining a set of tasks to use these systems and understand the order is which to use these system, in other words, Terraform must run before Ansible in this case.
So an ‘Orchestrator of Orchestrators’ (OoO or O3).
When a input is received by the workflow engine to start a job on a template, it is called a workflow request.
Inputs
We have three inputs into the engine.
- REST API Payload
- Templates
- Tasks
Lets go through each of these first then return to the core detail of the engine.
Tasks
A ‘Task’ is a Python module that focuses on a single task in that it does not (or should) not make multiple calls to an external system where each call would be defined as a call that would create, modify or delete resources. A call can create multiple resources of the same type for example, but not different resources or actions. That’s confusing, so lets clarify this with an example using the Terraform TFE REST API.
When we use the Terraform REST API (PTFE) to apply a ‘Run’ we have to take 5 steps (REST API calls) to have the job start. The ordered steps (calls/actions) we make are:
- Get the workspace ID by name
- Create a Workspace configuration version
- Create and upload the workspace configuration files
- Start a PTFE run with uploaded configuration files, wait for PTFE plan
- Apply the PTFE run plan, wait (poll) for completion status
Each workflow engine task will perform only one of these actions. So for this simple TFE case, we have 5 tasks, which translate into 5 Python task files. The reasoning behind this is that each task becomes autonomous and reusable. For example the first task ‘Get the workspace ID by name’ can be reused in a number of different TFE actions. For most TFE actions, we need to get the workspace ID before we can perform any other tasks on TFE. We will see in the next section on templates how this works.
The Python worker task is a class module that is sub-classed from an abstract ‘Task’ class. This parent class defines the required methods of the worker task class and adherence to this is checked upon loading the task on system startup. These tasks are ‘drop ins’ so to create a new task, we write and test the task and drop it into a task folder, the task is automatically registered with the system on startup.
The abstract Task class also inherits from a ‘State’ class. This state class uses Redis to override the usual Python variable getattr and setattr methods. The state class uses Redis to store the variables for the task class instead of the usual class __dict__. The reason for this is so we have stateful variables, stateful in regard to the fact that even after the task terminates (successfully, failure or exception) the ‘state’ of the task is saved. So taking the example that an exception occurs during the engine executing the templates tasks, when the templates tasks are restarted the previous state is is invoked. This prevents having tasks to re-run and potentially create multiple end system tasks. Let use Ansible as an example.
When we use the Ansible AWX/Tower API to submit a job template to run via the REST API, a job ID is returned to the task for the submission so the task can track it by polling the status of the job ID. Now, lets assume the host the engine is running on crashes after a task has submitted a job template run to Ansible AWX/Tower and a job ID was reported back but before the Ansible job finished. When the workflow engines host restarts and the workflow engine restarts, it will detect that there was a workflow request previously running but not completed. The engine will restart the request. Now as each task in the request template will be re-run, the last thing we want if for this Ansible task to restart fully, in other words submit a new job template run request to Ansible AWX/Tower, we would get a new job ID and have two jobs running on Ansible AWX/Tower. So as we have stateful variable backed by the State class and Redis, when the engine task for an Ansible job restarts it will check its variable job_id and find a valid (non None) value, it then understands that the job has already been submitted to Ansible and it only needs to poll for the result.
A lot of words again. Lets look at a version of Workflow Engine Ansible AWX task code with the key components.
"""
Implements custom task for AWX job
"""
from service.wflow.task import Task, Tasks
from common.states import *
import json
import requests
import urllib3
import re
@Tasks(task_name="awx_job_launch")
class task_awx_job(Task):
"""
Provides the AWX job launch and job status polling.
Expects state variables of the following to be made available by the engine during task creation:
awx_url (str)
job_template_id (int)
extra_vars (dict) - this AWX extra_vars payload.
"""
def task_init(self):
""" """
self.create_state_attr("awx_jobid", 0, public=False)
self.awx_to_dag_status_map = {
"new": "created",
"pending": "running",
"waiting": "running",
"running": "running",
"successful": "successful",
"failed": "failed",
"error": "failed",
"canceled": "canceled",
}
def ping(self):
"""
Call AWX /jobs/xxxx to get status of job
"""
# if we already have a terminal state just return state
if self.task_state in ["successful", "failed", "canceled", "exception"]:
return self.task_state
url = "{}/api/v2/jobs/{}/".format(self.awx_url, self.awx_jobid)
self.flog.log("AWX Task Job Status URL: {}".format(url))
headers = {
"content-type": "application/json",
"Authorization": "Bearer {}".format(self.awx_token),
}
r = requests.get(url, headers=headers, verify=False)
json_resp = {}
if r.status_code == 200:
json_resp = json.loads(r.content)
self.task_state = self.awx_to_dag_status_map[json_resp["status"]]
# if a terminal state (successful, failed, error, canceled) we could get the job status,
# then get the stdout and log to task log
if json_resp["status"] in ["successful", "failed", "error", "canceled"]:
self.get_awx_job_stdout(json_resp["related"]["stdout"])
else:
self.task_state = "failed"
self.flog.log(
"Task Ping: AWX job '{}' Payload: '{}'.".format(
self.awx_jobid, json.dumps(json_resp, indent=2)
)
)
# if status means the task has terminated (succesfully or not),
# dump the returned payload from AWX
if (
json_resp["status"] in ["successful", "failed", "error", "canceled"]
or self.task_state == "failed"
):
self.flog.log(
"Task Ping Payload Dump: AWX job '{}' Payload: '{}'.".format(
self.awx_jobid, json.dumps(json_resp, indent=2)
)
)
if json_resp["status"] == "successful":
self.slog.info("AWX job {} completed successfully.".format(self.awx_jobid))
else:
self.slog.info("AWX job {} failed.".format(self.awx_jobid))
self.slog.error(
"AWX job id {} failed with reason: {}".format(self.awx_jobid, r.text)
)
self.flog.log(
"Task Ping: AWX job '{}' AWX Status: '{}' Task Status: {}.".format(
self.awx_jobid, json_resp["status"], self.task_state
)
)
return self.task_state
def run(self):
"""
Launch AWX Job Template With Params
"""
self.flog.log("{} - always_run = {}".format(self.name, self.always_run))
self.flog.log("Task State {}".format(self.task_state))
if self.task_state in ["running", "waiting"]:
self.flog.log("Task is already in progress, state is [{}]. ".format(self.task_state))
return
self.flog.log("task_awx_job: Running Task ID {}\tName: {}".format(self.uuid, self.name))
previous_task_state = self.last_task_state
self.flog.log("Previous task state was '{}'".format(previous_task_state))
# if this task ran before with previous state of ...
if (
previous_task_state
in ["waiting", "successful", "exception", "failed", "canceled", "timeout"]
and self.awx_jobid > 0
):
# relaunch job
self.flog.log("Relaunching job id '{}'".format(self.awx_jobid))
url = "{}/api/v2/jobs/{}/relaunch/".format(self.awx_url, self.awx_jobid)
self.flog.log("AWX Task Job Relaunch URL: {}".format(url))
payload = {}
else:
# launch new job
# must be last state of 'never' or (task) 'created' but never got to 'running' state
self.flog.log("Launching new job template '{}'".format(self.job_template_id))
url = "{}/api/v2/job_templates/{}/launch/".format(self.awx_url, self.job_template_id)
self.flog.log("AWX Task Job Launch URL: {}".format(url))
# get task specific params that should have been passed when task was created
extra_vars = (
self.extra_vars
) # object in state so we have to get the full object before using
payload = {"extra_vars": "{}".format(extra_vars)}
headers = {
"content-type": "application/json",
"Authorization": "Bearer {}".format(self.awx_token),
}
r = requests.post(url, data=json.dumps(payload), headers=headers, verify=False)
json_resp = {}
# possible return codes (others 404 500)
# Launch: 201, 400, 403 (405?)
# ReLaunch: 201, 403
if r.status_code == 201:
json_resp = json.loads(r.content)
self.awx_jobid = json_resp["id"]
self.task_state = "running"
self.flog.log(
"AWX job template '{}' launched with AWX job status code: '{}'.".format(
self.job_template_id, json_resp["status"]
)
)
self.slog.info("AWX job {} launched successfully.".format(self.awx_jobid))
else:
self.task_state = "failed"
self.flog.log(
"AWX job template '{}' launch failed with HTTP status code: '{}' '{}'. Payload: \n{}".format(
self.job_template_id, r.status_code, r.text, json.dumps(json_resp, indent=2)
)
)
if r.status_code == 400:
json_resp = json.loads(r.content)
variables_needed_to_start = json_resp["variables_needed_to_start"]
msg = "The AWX job failed due to missing variables: '{}'.".format(
",".join(variables_needed_to_start)
)
elif r.status_code == 403:
msg = "The AWX job failed due to lack of permissions"
elif r.status_code == 404:
msg = "The AWX job failed as the job id '{}' or template id: {} was not found.".format(
self.awx_jobid, self.job_template_id
)
else:
msg = "The AWX job failed due to an unknown error: {}: {}".format(
r.status_code, r.content
)
self.slog.error(msg)
return
def cancel(self):
"""
Call AWX Job /jobs/xxxx/cancel
"""
self.task_state = "canceled"
url = "{}/api/v2/jobs/{}/cancel/".format(self.awx_url, self.awx_jobid)
self.flog.log("AWX Task Job Status URL: {}".format(url))
headers = {
"content-type": "application/json",
"Authorization": "Bearer {}".format(self.awx_token),
}
r = requests.get(url, headers=headers, verify=False)
self.slog.warning(
"Task Cancel: AWX job '{}' cancelled upon request by workflow.".format(self.awx_jobid)
)
The task class ‘task_awx_job’ inherits from the ‘Task’ class as we discussed. There is a class wrapper called ‘Tasks’ which has a parameter of task_name. This parameter defines the name what will be used to identify the class task in the templates.
There are four methods shown (some non-required methods removed for brevity), these are required and enforced by the inherited Task class. These methods are called by the engine when required after the class instantiation. Let look at each of these in turn.
task_init
This replaces the usual __init__ method and is expected that any custom initialization required by the class will be done here. It should be used as if it is the __init__ method. the __init__ method should not be defined in the task class, this is due to the way the class is instantiated by the engine. The first line of code in this method calls an inherited class method ‘create_state_attr’, which as the name suggests creates a variable called ‘awx_jobid’ in the state store backed by Redis. This allows variables to be created in the usual way like ‘self.my_var=2’ which will not be stateful, but declaring a state var means as discussed before it will persist between instances of this workflow request using this task. Access to the variable after creation is no different that usual. i.e. print(awx_jobid).
The task_init method is called by the workflow engine when it wants the class to initialize itself. This is always the first call into the class by the engine.
ping
The ping method is called by the engine get the status of the running task. This is both to check the task is still running (not stalled, crashed etc) and to get the current task status. The task status must be one of a pre-defined set of engine task states, so the task may need to map the external system statuses with the engine statuses which we can see this map between AWX job statuses and the engine statuses in the task_init method in variable ‘awx_to_dag_status_map’
In short, the code in the ping method polls AWX for the job ID and returns a mapped engine status to the engine. You also see some logging methods used here which are inherited from the Task class, this logging is stored in task specific log files. Each workflow request and each task is given a UUID after which the file is named and internal logs are tagged with.
The ping method is called after the run method.
run
The run method is called by the engine after task_init and is an instruction to the class to start whatever task it needs to perform. In this case this is an Ansible AWX template task, so the run method creates the HTTP request to Ansible AWX with the payload required for the AWX template and POST’s to AWX. The method then receives a job ID in response to the request and saves this job ID in the ‘awx_jobid ‘ var which we know from the task_init section that this is a stateful variable.
The task status is then updated to reflect the status provided by AWX but mapped to an engine status.
cancel
If for any reason the engine decides the task must cancel what it is doing, the cancel method is called. This is in response to a user of the system attempting to cancel a running workflow request but it could be in response to a graceful system termination event.
Templates
Templates define the tasks to run, a template identifier is the entity that is passed to the engine via the REST API to create a new workflow request.
A template defines the tasks to be run and the order of these either implicitly or explicitly. The engine uses the template to create a Directed Acrylic Graph (DAG) to create the run order of the tasks.
Firstly, lets use a simple example, there is a system task called ‘noop’, which its only job is to sleep for a specified time after which it reports back successful. Its used as a test task so we are not always calling out to a external system just to test the engine. So firstly let look at the ‘noop’ task.
"""
Implements noop task
"""
from service.wflow.task import Task, Tasks
from common.states import *
from datetime import datetime
import random
@Tasks(task_name="noop")
class noop(Task):
""" """
def task_init(self):
""" """
self.t1 = None
self.t2 = None
# self.runtime_delay = 20
def ping(self):
"""
Call AWX /jobs/xxxx to get status of job
"""
# if we already have a terminal state just return state
if self.task_state in ["successful", "failed", "canceled", "exception"]:
return self.task_state
self.t2 = datetime.now()
runtime = (self.t2 - self.t1).total_seconds()
if runtime > self.runtime_delay:
self.slog.info(
"NOOP task completed successfully at {}. for {} s".format(
self.t2.strftime("%H:%M:%S"), runtime
)
)
rand_no = random.randrange(0, 1000)
self.create_or_update_state_attr("rand_no", rand_no, public=False)
self.flog.log("Task Generated Random Number {}".format(rand_no))
self.task_state = "successful"
return self.task_state
def run(self):
""" """
self.flog.log("self.runtime_delay time is: {}".format(self.runtime_delay))
try:
self.flog.log("Task Random Number {}".format(self.rand_no))
except Exception as e:
self.flog.log("No variable 'rand_no' exists")
self.flog.log("{} - always_run = {}".format(self.name, self.always_run))
self.flog.log("Task State {}".format(self.task_state))
# if self.task_state in ['running', 'waiting']:
# self.flog.log("Task is already in progress, state is [{0}]. ".format(self.task_state))
# return
self.task_state = "running"
self.t1 = datetime.now()
self.slog.info("NOOP task launched successfully at {}.".format(self.t1.strftime("%H:%M:%S")))
return
def cancel(self):
""" """
# self.slog.error(msg)
self.task_state = "canceled"
After the previous discussion on Tasks, this will seem fairly obvious as to what it does. So lets look at a template that uses this Task.
{
"name": "NOOP Template Run",
"ref_name": "noop_template_run",
"description": "Run no-op tasks",
"schema_version": 1,
"workflow": {
"input": {
"global": {
"runtime_delay": 60,
"expires": "${workflow.input.global_delay}"
}
}
},
"tasks": [
{
"name": "no op task #1",
"ref_name": "noop_01",
"description": "Launches a noop task #1",
"class": "noop",
"input": {
"runtime_delay": "${workflow.input.delay}"
},
"always_run": false,
"depends_on": [],
"optional": false
},
{
"name": "no op task #2",
"ref_name": "noop_02",
"description": "Launches a noop task #2",
"class": "noop",
"input": {
"runtime_delay": "${workflow.input.delay}"
},
"always_run": false,
"depends_on": [],
"optional": false
},
{
"name": "no op task #3",
"ref_name": "noop_03",
"description": "Launches a noop task #3",
"class": "noop",
"input": {
"runtime_delay": "${workflow.input.delay}",
"rand_no": "${noop_01.output.rand_no}",
"rand_no2": "${noop_02.output.rand_no}"
},
"always_run": false,
"depends_on": [],
"optional": false
}
]
}
This template defines some metadata about the template including the ref_name, which is the identifier of the template in a request via the API. The templates are loaded by the system on startup and registered by the ref_name value.
There is a ‘workflow’ key, which defines some workflow input values at a global level. These values will be used for tasks that do not have any values provided specifically for the task via the workflow request submission.
When a workflow request is submitted to the engine, it expects that values are passed as part of the request to fulfil these requirements. So the engine expects that for each task values are passed to the required input variables. For example, the first task ‘no op task #1’, expects to have the variable ‘runtime_delay’ available with a value. This value is obtained from the workflow request submission and would be defined as a named variable called ‘delay’. The input variables are mapped to the key defined in the task, so the input variable ‘delay’ value will be assigned to a state variable in the task called ‘runtime_delay’. Now if the variable (and value) ‘delay’ is not passed as part of the submission, the task variable ‘runtime_delay’ will be assigned the value ’60’ as defined in the global workflow input.
As mentioned, the engine creates a DAG from the template for an ordered running of tasks. Tasks will be run based on this order but importantly where one or more tasks dependencies have been satisfied, tasks will be run in parallel.
Task dependencies are gleaned from the required variables in each task. Looking at task ‘no op task #3’, its input variables require the output from task noop_01 and noop_02, specifically the values from the tasks ‘rand_no’. The engine understands this via the DAG and ensures completion of the parent tasks and on successful completion of all parents, it will populate the dependant task state variables as defined in the task template, then run the task.
Note, here all tasks are using the same Task ‘noop’ as defined in the task ‘class’ key. Each task uses its own instance of the ‘noop’ class, the dependent output variables are matched using the unique task names.
If we wanted a task to run in a specific part of the work flow request (or specific step in the DAG) but this task has no variable dependencies, then the task ‘depends_on’ list can be populated with the unique names of the tasks which instructs the engine whilst creating the DAG to honor these explicit dependencies and insert the task in the correct place in the DAG.
This template would have the tasks #1 & #2 run in parallel and after both completing successfully, task #3 would be run.

We looked at the Ansible AWX Task in the previous section, the template is a lot more simple to run a single AWX job template.
{
"name": "AWX Job Template Run",
"ref_name": "awx_job_template_run",
"description": "Run an AWX Job Template",
"schema_version": 1,
"tasks": [
{
"name": "Launch Job Template",
"ref_name": "launch_job_template",
"description": "Launches an AWX Job Template",
"class": "awx_job_launch",
"input": {
"awx_url": "${workflow.input.awx_url}",
"job_template_id": "${workflow.input.job_template_id}",
"extra_vars": "${workflow.input.extra_vars}",
"awx_token": "${workflow.input.awx_token}"
},
"always_run": false,
"depends_on": [],
"optional": false
}
]
}
We also spoke about the Terraform TFE having many steps, the Terraform PTFE run template looks like this.
{
"name": "Virtual Machine Template",
"ref_name": "tfe_virtual_machine_template",
"description": "Virtual machine CRUD using Terraform",
"schema_version": 1,
"tasks": [
{
"name": "Workspace ID Task",
"ref_name": "workspace_id_task",
"description": "Get the workspace id by name",
"class": "tfe.workspace_id",
"input": {
"tfe_server": "${workflow.input.tfe_server}",
"tfe_bearer_token": "${workflow.input.tfe_bearer_token}",
"organization_name": "${workflow.input.organization_name}",
"workspace_name": "${workflow.input.workspace_name}"
},
"always_run": false,
"depends_on": [],
"optional": false
},
{
"name": "Workspace Configuration Version",
"ref_name": "workspace_configuration_version",
"description": "Creates a workspace configuration version",
"class": "tfe.workspace_config_version",
"input": {
"tfe_server": "${workflow.input.tfe_server}",
"tfe_bearer_token": "${workflow.input.tfe_bearer_token}",
"workspace_id": "${workspace_id_task.output.workspace_id}"
},
"always_run": true,
"depends_on": [],
"optional": false
},
{
"name": "Upload Workspace Configuration",
"ref_name": "workspace_config_file_upload",
"description": "Creates & Uploads the workspace configuration files",
"class": "tfe.workspace_upload_config_files",
"input": {
"tfe_server": "${workflow.input.tfe_server}",
"tfe_bearer_token": "${workflow.input.tfe_bearer_token}",
"config_url": "${workspace_configuration_version.output.config_version_url}",
"file_url": "${workflow.input.file_url}",
"file_hash": "${workflow.input.file_hash}"
},
"always_run": false,
"depends_on": [],
"optional": false
},
{
"name": "Start a PTFE Run",
"ref_name": "workspace_run",
"description": "Starts a PTFE run with uploaded configuration files, waits for plan",
"class": "tfe.workspace_run",
"input": {
"tfe_server": "${workflow.input.tfe_server}",
"tfe_bearer_token": "${workflow.input.tfe_bearer_token}",
"workspace_id": "${workspace_id_task.output.workspace_id}",
"config_version_id": "${workspace_configuration_version.output.config_version_id}"
},
"always_run": false,
"depends_on": ["workspace_config_file_upload"],
"optional": false
},
{
"name": "Apply a PTFE Run",
"ref_name": "workspace_run_apply",
"description": "Applies a PTFE run with, waits for completion",
"class": "tfe.workspace_run_apply",
"input": {
"tfe_server": "${workflow.input.tfe_server}",
"tfe_bearer_token": "${workflow.input.tfe_bearer_token}",
"run_id": "${workspace_run.output.run_id}"
},
"always_run": false,
"depends_on": [],
"optional": false
}
]
}
Notice that the Terraform PTFE template task named ‘workspace_run’ used the explicit dependency feature, as it depends on the PTFE ‘workspace_config_file_upload’ task completing before it runs. It does not declare any input variable values from that task. So this ensures that this task only runs after all input variables can be populated AND the explicit dependency on the successful completion of the ‘workspace_config_file_upload’ task is satisfied.
Workflow Engine REST API
The Workflow Engine has a REST API interface, this is used for all external interaction with the engine for submission of requests, request statuses, log retrieval, etc.
We will continue with the ‘noop’ example as its less complex than PTFE and a little more interesting that the single AWX job.
There are a few entry points to create a workflow request, each request is also assigned a revision number so we can update the original request and run against a new revision but have the tracking / audit capability too. We can just submit the request for validation only, or validation and submission. We can also schedule a date and time for the request to be run. In this example we will validate and submit in one post for immediate execution.
We submit the following payload via a POST at a url:
https://dev01.labs.haystacknetworks.com/api/v1/workflow/submit/
{
"workflow": {
"meta": {
"ref": "bb0fbf06d5284fbbb16baeb452652100",
"name": "api noop",
"template": "noop_template_run",
"trace_id": "bb0fbf06d5284fbbb16baeb452652100",
"description": "VM Build 3",
"template_schema_version": 1
},
"vars": {
"global": {
"input": {
"global_delay": 600,
"not_mapped": "available",
"expires": 89009
}
},
"workflow": {
"input": {
"wflow_priv_var": "my_wflow_var"
}
}
},
"schedule": {
"when": "now",
"start": ""
}
},
"tasks": {
"noop_01": {
"vars": {
"input": {
"delay": 30,
"ignored": "will not copy over as not in template"
}
}
},
"noop_02": {
"vars": {
"input": {
"delay": 30,
"ignored_as_well": "will not copy over as not in template"
}
}
},
"noop_03": {
"vars": {
"input": {
}
}
}
},
"schema_version": 2
}
You can see the tasks and the variable definitions and how they map to the template we discussed in the previous section. The template is defined in the ‘template’ key value.
The ‘traceid’ field is a UUID from the wider system that is submitting this request to the engine. This trace ID is created after a resource request submission into the wider orchestration system and is used to track any actions performed on the request end to end.
The ‘ref’ field is a unique reference from the calling system for this request. Its entirely possible and expected that two or more unique requests will have the same trace ID. This way having unique internal requests but a ID (trace ID) to track the entire process.
Next…
As we are using declarative files for templates, a ‘feature’ on the list I want to look at is the ability to submit the template as part of the REST API submission. This would mean calling systems could create their own template, defining what tasks and order to run in. I need to think about being able to scrape metadata from the tasks via the API for an external system to use to create the template, but not beyond the realms on possibility.
I want to write a little more about the internal workings of the engine and how it achieves all this in a separate discussion. I hope that this discussion has given an insight into my thinking and a little more around the architectural thinking on how the engine should work.
I see the workflow engine as the core of any orchestrator regardless of the tier in the workflow it sits at. Also having the core engine requiring no modification to add (drop) in additional resource code (tasks) and having the engine core being blind to what resources are being created, just knowing what tasks to run, in what order and having the ability to manage and monitor the tasks and report back.
Maybe the clever people at Red Hat (AWX/Tower), HashiCorp (Terraform), Azure, AWS, GCP will correct me on my architectural thinking 🙂 , but in any case the engine alone has been an interesting journey (and not over by a long shot). I certainly have had inspiration from some of the platforms I just mentioned but in addition the Luigi project. The end to end system which I will write more about has been equally interesting and challenging.